




PPC для сверхразумов | Александр Хитро
12 лет в рекламе
@podorozhnik_ppc
Автор t.me/ppc_bigbrain/865
Меню t.me/ppc_bigbrain/1191
Чат t.me/+IAE-w7o7tZtjOTNi
Подписка
t.me/ppc_bigbrain/1496
t.me/ppc_bigbrain/1497
Отзывы
t.me/ppc_bigbrain/1004
t.me/ppc_bigbrain/1249
Комбайн
t.me/ppc_bigbrain/1582 Связанные каналы | Похожие каналы
3 897
подписчиков
Популярное в канале

Ликбез по [квадратным] [скобкам] в Директе: суть, результаты, аналитика. 😶😶😶😶😶😶😶 😶😶😶😶 😶😶😶😶 😶😶...

если это не база, то что это via @ppc_bigbrain
Так прикольно. Один из редких случаев, когда реально ввожу поисковый запрос с целью заказать под ...
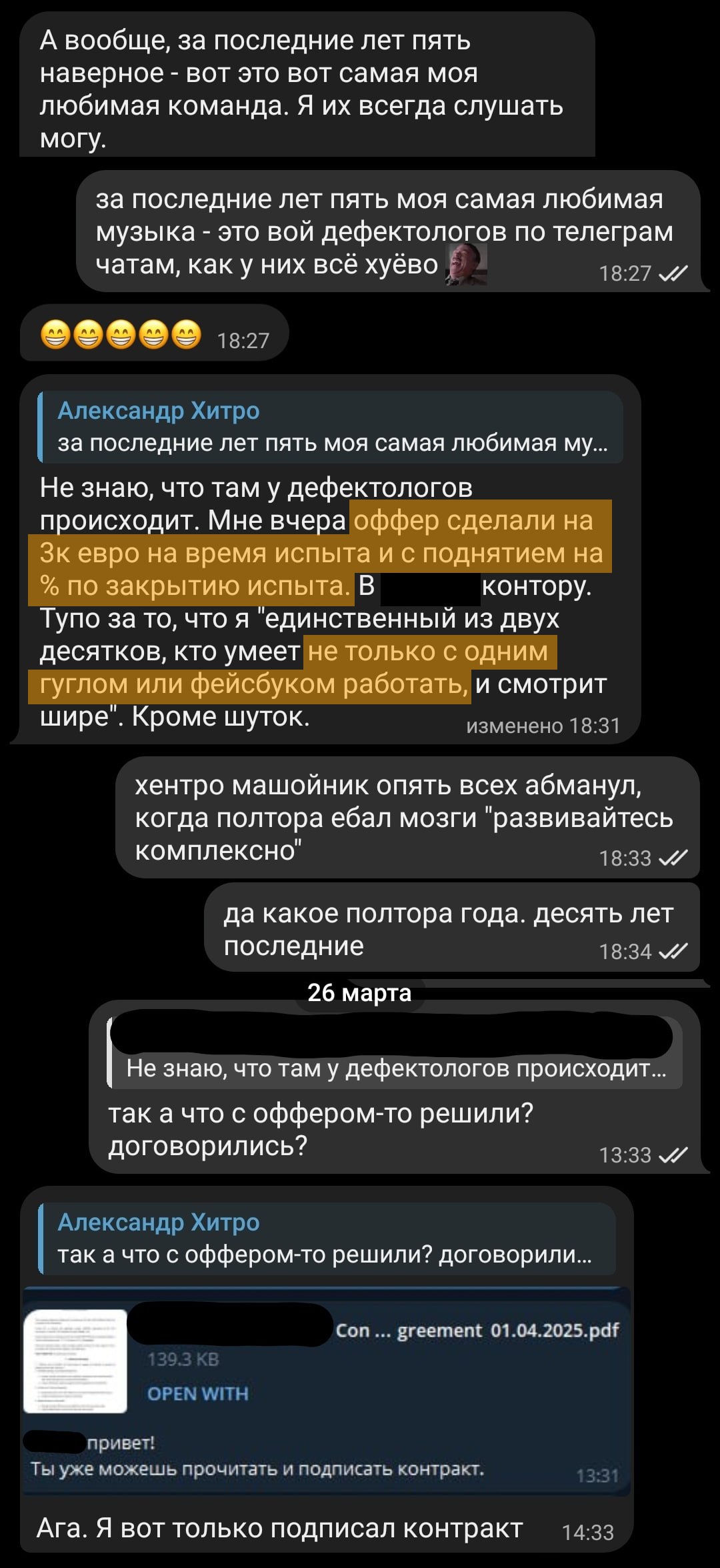
«Оффер сделали на 3к евро с поднятием на % после испыта». Если вы хотите раздавать такую же люте...

реклама в инстаграме, что б я без тебя делал-то чот реву псдтс го конкурс на лучшую шутку в ком...