
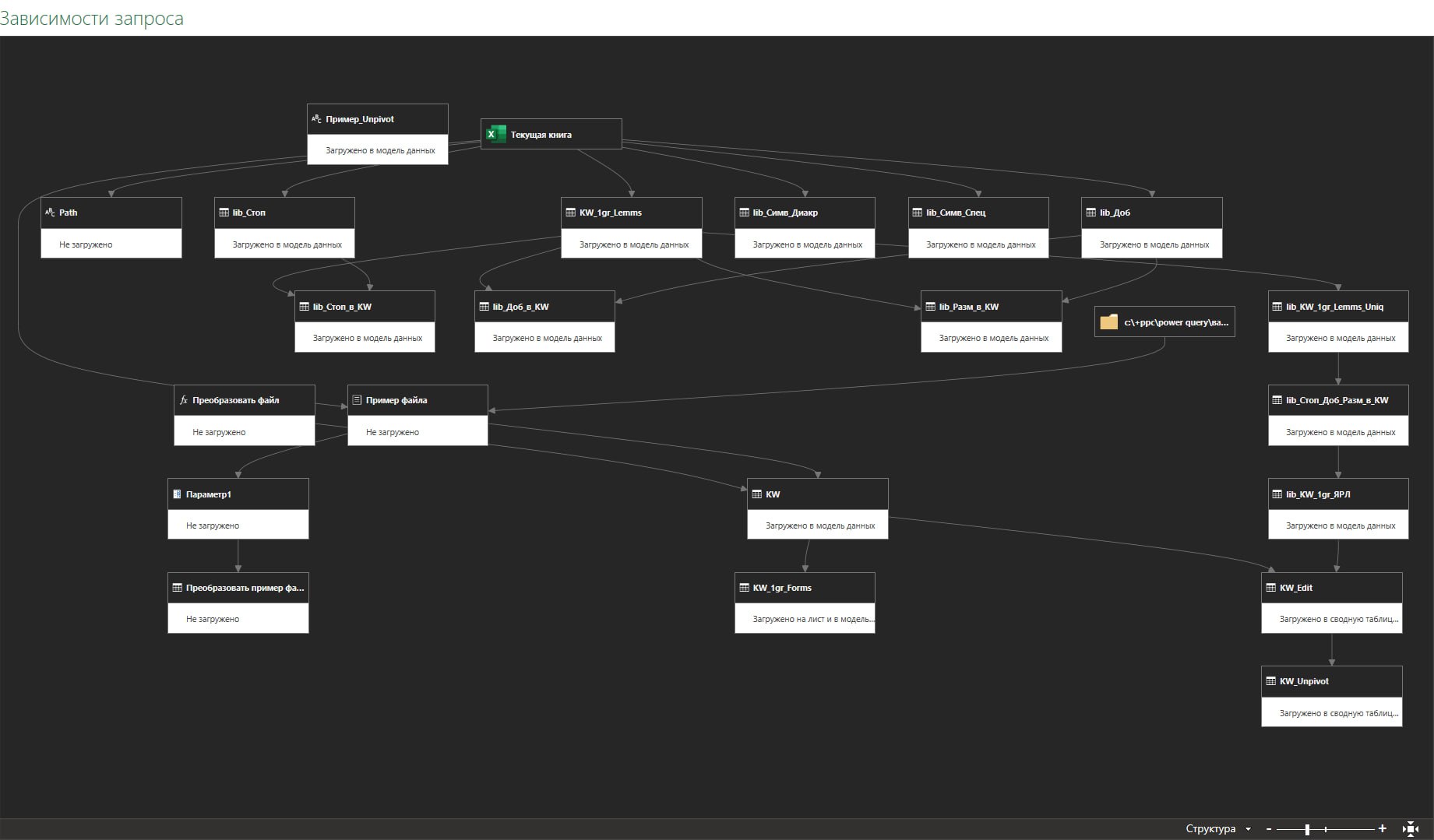
↖️ 125 операций теперь за 1 минуту и 1 клик: обработка семантики в Power Query.
За последние сутки просидел 20 часов в Power Query и сделал нечто абсолютно потрясающее.
Я неоднократно рассказывал о турбокомбайне (часть 1, часть 2, часть 3, часть 4, часть 5), в котором автоматически очистил 70 тысяч фраз, и из них сгруппировал 35 тысяч фраз за 3,5 минуты.
И думал тогда, что создал гениальную нанотехнологию. Да, это был огромный прыжок для всего человечества в сторону автоматизации, но я знал, что можно не только его ускорить в несколько раз, но и довешать туда выполнение ещё пары сотен важных процессов.
————————
Как прошли мои последние три недели угара и содомии:
1️⃣ Раз десять брался за переделывание шаблона с полного нуля.
2️⃣ Каждый раз открывал все созданные запросы (код с шагами обработки на языке M в Power Query), видел новые дыры и понимал, что нужно сделать оптимальнее.
3️⃣ Шёл переделывать всё с нуля.
4️⃣ Смотрел взахлёб ролики на Ютубе на все схожие темы, которые могли относиться к нужным мне операциям.
5️⃣ Насмотрелся на то, что вытворяют на языке M забугорные профессионалы BI-разработки.
6️⃣ Понял, как оптимизировать множество процессов, а какие-то вовсе удалить.
7️⃣ Сотни раз пытался генерить в ChatGPT код и отдельных функций, и больших сложных процессов из нескольких десятков шагов преобразования данных.
8️⃣ Почти добился того, чтобы ChatGPT меня слушался и генерил сразу то, что мне нужно, без лишних правок, но от количества исправлений и переделываний захотелось немножечко суецыднуться.
9️⃣ Несмотря на сотни попыток сгенерить код в ChatGPT, взял за основу его код только для пары функций, которые составили ~10% кода, всё остальное сделал сам.
1️⃣0️⃣ В 2 раза уменьшил количество запросов и подключений к источникам (см. скрин выше).
1️⃣1️⃣ Сделал код более читабельным.
1️⃣2️⃣ Параметризировал функциями много чего, но ещё не всё.
1️⃣3️⃣ Универсализировал преобразования и вычисления.
1️⃣4️⃣ Предусмотрел множество пользовательских сценариев.
1️⃣5️⃣ Сделал сквозную взаимосвязь всех запросов друг с другом.
1️⃣6️⃣ В 1 клик за 1 минуту обновляется весь пайплайн.
1️⃣7️⃣ Предусмотрел важные вещи для удобства использования на последующих шагах.
1️⃣8️⃣ Почти в 3 раза сократил общий объём кода до 470 строк в сравнении с 1300 строками в прошлой версии.
1️⃣9️⃣ Сделал сквозной пайплайн из 125 операций преобразования данных.
2️⃣0️⃣ Уменьшил количество шагов в каждом запросе до одного.
2️⃣1️⃣ В 3 раза сократил время отработки запроса.
2️⃣2️⃣ Сделал упор на пользовательский опыт, т.к. делаю всё это уже не для себя, а для вас.
————————
Челлендж офигеть какой интересный, освоил много нового.
Ах да, чуть не забыл о результатах.
🚫 Прошлая версия, которую сделал 3 месяца назад, обрабатывала грязные спарсенные 70 тысяч фраз и группировала целевые 35 тысяч фраз за 3,5 минуты.
Не бомбите на количество фраз, я уже говорил, что тестирую пайплайн специально на больших объёмах, чтобы видеть дыры в производительности. Уникальных поисковых запросов в любом рекламном кабинете всё равно гораздо больше, и нужно быть готовым к тому, что придётся как-то с ними работать.
✅ Новую версию тестировал на грязном массиве из 50 тысяч фраз, и она отработала за 1 минуту 10 секунд.
✅ Ускорил пайплайн ровно в 3 раза. При этом операций было выполнено даже больше, чем раньше.
————————
Пока вдохновение есть, за ближайшую неделю довешаю сюда ещё под сотню-две операций.
Никогда не думал, что дойду до того, что моя мечта всё это автоматизировать и сделать комбайн не только для себя, а для людей, станет реальностью, но релиз всё ближе.
via @ppc_bigbrain
За последние сутки просидел 20 часов в Power Query и сделал нечто абсолютно потрясающее.
Я неоднократно рассказывал о турбокомбайне (часть 1, часть 2, часть 3, часть 4, часть 5), в котором автоматически очистил 70 тысяч фраз, и из них сгруппировал 35 тысяч фраз за 3,5 минуты.
И думал тогда, что создал гениальную нанотехнологию. Да, это был огромный прыжок для всего человечества в сторону автоматизации, но я знал, что можно не только его ускорить в несколько раз, но и довешать туда выполнение ещё пары сотен важных процессов.
————————
Как прошли мои последние три недели угара и содомии:
1️⃣ Раз десять брался за переделывание шаблона с полного нуля.
2️⃣ Каждый раз открывал все созданные запросы (код с шагами обработки на языке M в Power Query), видел новые дыры и понимал, что нужно сделать оптимальнее.
3️⃣ Шёл переделывать всё с нуля.
4️⃣ Смотрел взахлёб ролики на Ютубе на все схожие темы, которые могли относиться к нужным мне операциям.
5️⃣ Насмотрелся на то, что вытворяют на языке M забугорные профессионалы BI-разработки.
6️⃣ Понял, как оптимизировать множество процессов, а какие-то вовсе удалить.
7️⃣ Сотни раз пытался генерить в ChatGPT код и отдельных функций, и больших сложных процессов из нескольких десятков шагов преобразования данных.
8️⃣ Почти добился того, чтобы ChatGPT меня слушался и генерил сразу то, что мне нужно, без лишних правок, но от количества исправлений и переделываний захотелось немножечко суецыднуться.
9️⃣ Несмотря на сотни попыток сгенерить код в ChatGPT, взял за основу его код только для пары функций, которые составили ~10% кода, всё остальное сделал сам.
1️⃣0️⃣ В 2 раза уменьшил количество запросов и подключений к источникам (см. скрин выше).
1️⃣1️⃣ Сделал код более читабельным.
1️⃣2️⃣ Параметризировал функциями много чего, но ещё не всё.
1️⃣3️⃣ Универсализировал преобразования и вычисления.
1️⃣4️⃣ Предусмотрел множество пользовательских сценариев.
1️⃣5️⃣ Сделал сквозную взаимосвязь всех запросов друг с другом.
1️⃣6️⃣ В 1 клик за 1 минуту обновляется весь пайплайн.
1️⃣7️⃣ Предусмотрел важные вещи для удобства использования на последующих шагах.
1️⃣8️⃣ Почти в 3 раза сократил общий объём кода до 470 строк в сравнении с 1300 строками в прошлой версии.
1️⃣9️⃣ Сделал сквозной пайплайн из 125 операций преобразования данных.
2️⃣0️⃣ Уменьшил количество шагов в каждом запросе до одного.
2️⃣1️⃣ В 3 раза сократил время отработки запроса.
2️⃣2️⃣ Сделал упор на пользовательский опыт, т.к. делаю всё это уже не для себя, а для вас.
————————
Челлендж офигеть какой интересный, освоил много нового.
Ах да, чуть не забыл о результатах.
🚫 Прошлая версия, которую сделал 3 месяца назад, обрабатывала грязные спарсенные 70 тысяч фраз и группировала целевые 35 тысяч фраз за 3,5 минуты.
Не бомбите на количество фраз, я уже говорил, что тестирую пайплайн специально на больших объёмах, чтобы видеть дыры в производительности. Уникальных поисковых запросов в любом рекламном кабинете всё равно гораздо больше, и нужно быть готовым к тому, что придётся как-то с ними работать.
✅ Новую версию тестировал на грязном массиве из 50 тысяч фраз, и она отработала за 1 минуту 10 секунд.
✅ Ускорил пайплайн ровно в 3 раза. При этом операций было выполнено даже больше, чем раньше.
————————
Пока вдохновение есть, за ближайшую неделю довешаю сюда ещё под сотню-две операций.
Никогда не думал, что дойду до того, что моя мечта всё это автоматизировать и сделать комбайн не только для себя, а для людей, станет реальностью, но релиз всё ближе.
via @ppc_bigbrain